| OS: linux 7.5 DBMS: PostgreSQL 14.9 |
[목차여기]
PostgreSQL은 기본적으로 오라클에서 사용하는 SQL HINT 기능이 없지만
pg_hint_plan 을 설치하여 기본적인 hint는 사용 가능합니다.
rpm 파일 준비
rpm 파일 다운로드 및 사용 설명: https://github.com/ossc-db/pg_hint_plan
- 위 주소로 들어가서 오른쪽 표시한 부분을 누르면 지금까지의 모든 버전들을 볼 수 있습니다.
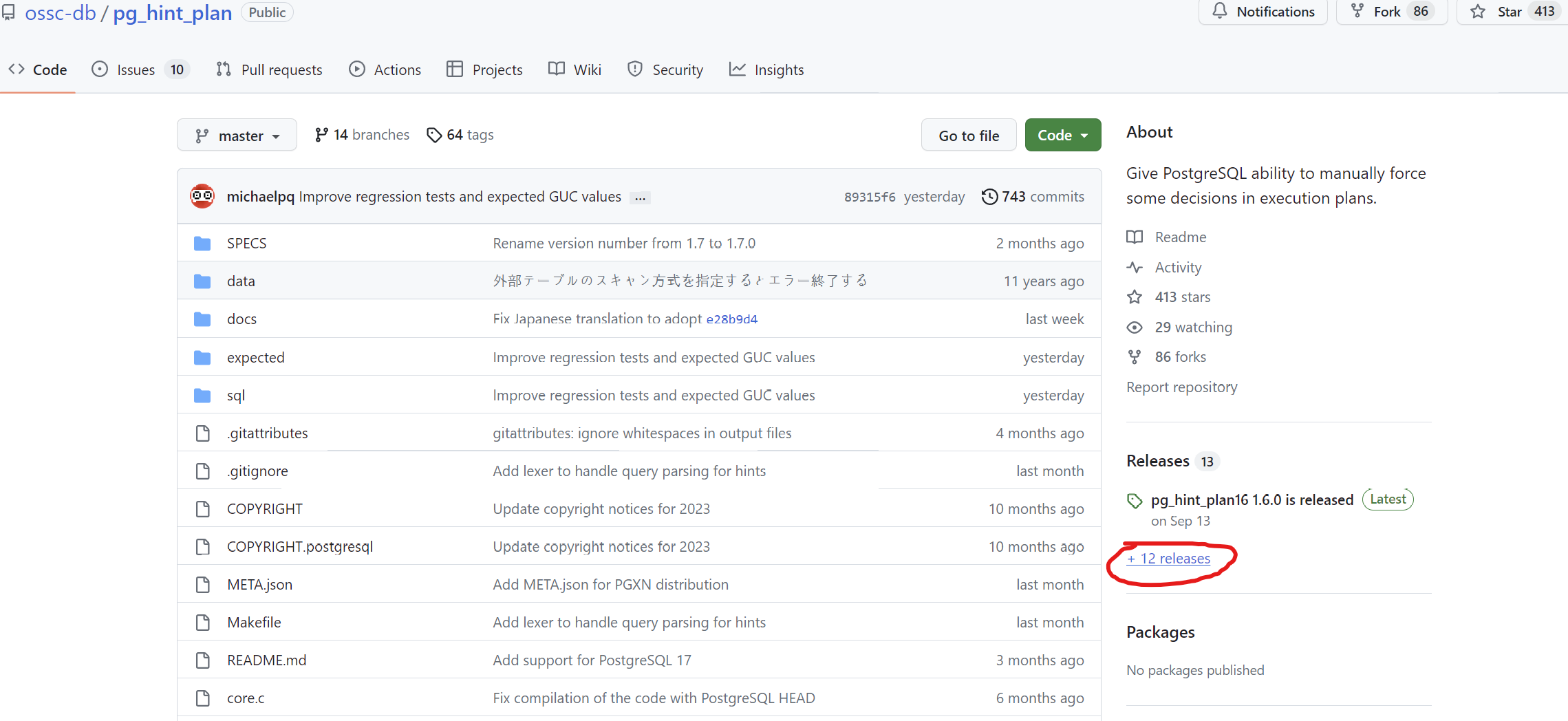
- 버전에 맞는 파일 다운로드 후 설치 진행
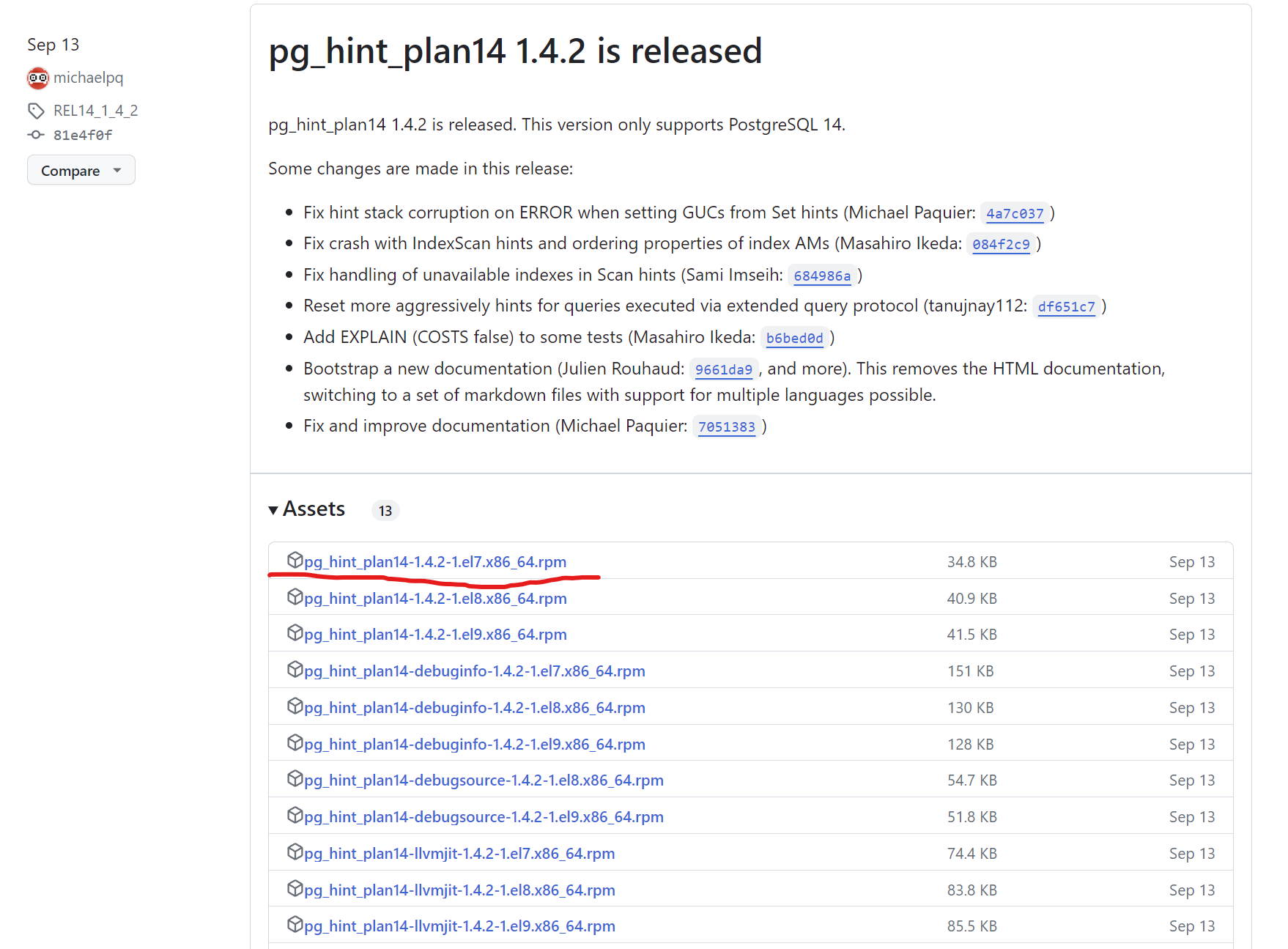
- rpm 파일 설치하면 /usr/pgsql-14/lib 같은 라이브러리 경로에 pg_hint_plan.so 파일이 생성됩니다.
[root@svr1 pgsql]# rpm -Uvh pg_hint_plan14-1.4.2-1.el7.x86_64.rpm
준비 중... ################################# [100%]
Updating / installing...
1:pg_hint_plan14-1.4.2-1.el7 ################################# [100%]
[root@svr1 pgsql]#
-- rpm 설치하면 pg_hint_plan.so 파일이 생성됨
[root@svr1 pgsql]# $ pwd
/usr/pgsql-14/lib
[root@svr1 pgsql]# ls -al | grep hint
-rwxr-xr-x. 1 root root 74896 9월 13 14:01 pg_hint_plan.so
1. pg_hint_plan module 설정 확인
shared_preload_libraries 값에 pg_hint_plan들어가 있어야 함, 설정 후 reload 또는 DB 재기동 시 적용됨
파라미터 편집(postgresql.conf) → pg_hint_plan 추가 → 변경사항저장 → DB재기동
RDS 환경에서는 파라미터 그룹 shared_preload_libraries 항목에서 pg_hint_plan 추가 후 DB재기동으로 간단히 적용 가능
select name, setting from pg_settings
where name in (
'shared_preload_libraries'
)
;
name | setting
--------------------------+--------------------------------------------------
shared_preload_libraries | pg_stat_statements,pg_cron,pg_hint_plan
2. SQL 실행계획 확인 방법
-- 예상 실행계획 확인(SQL은 수행 안함)
explain
select *
from sk.pg_stat_statements_hist a
where snap_id = 30
;
QUERY PLAN
---------------------------------------------------------------------------------
Seq Scan on pg_stat_statements_hist a (cost=0.00..8609.50 rows=3284 width=299)
Filter: (snap_id = 30)
(2 rows)
-- 실제 실행계획 확인(analyze 옵션 사용 시 SQL 수행되므로 주의)
explain (analyze, buffers)
select *
from sk.pg_stat_statements_hist a
where snap_id = 30
;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------
Seq Scan on pg_stat_statements_hist a (cost=0.00..8609.50 rows=3284 width=299) (actual time=6.903..34.769 rows=3352 loops=1)
Filter: (snap_id = 30)
Rows Removed by Filter: 120285
Buffers: shared hit=83 read=6985
I/O Timings: read=16.308
Planning Time: 0.072 ms
Execution Time: 35.019 ms
(7 rows)반응형
3. HINT 사용 예시
3.1 index_scan : 인덱스 사용 힌트
주의 : /*+ indexscan(a ix1) */ 힌트 구문 안에 테이블명, 인덱스명 등은 꼭 소문자로 적을 것(대문자 X)
-- pg_stat_statements_hist 테이블에는 3개의 인덱스가 존재
pskdb-> \d+ sk.pg_stat_statements_hist
Table "sk.pg_stat_statements_hist"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
---------------------+-----------------------------+-----------+----------+---------+----------+-------------+--------------+-------------
snap_id | bigint | | | | plain | | |
dt | timestamp without time zone | | | | plain | | |
userid | oid | | | | plain | | |
dbid | oid | | | | plain | | |
...
...
Indexes:
"pg_stat_statements_hist_ix1" btree (dt)
"pg_stat_statements_hist_ix2" btree (queryid, snap_id)
"pg_stat_statements_hist_ix3" btree (snap_id)
Access method: heap
-- 힌트 없이 실행
explain
select *
from sk.pg_stat_statements_hist a
where snap_id = 30
;
QUERY PLAN
---------------------------------------------------------------------------------
Seq Scan on pg_stat_statements_hist a (cost=0.00..8609.50 rows=3284 width=299)
Filter: (snap_id = 30)
(2 rows)
-- ix1 인덱스 사용 힌트(해당 인덱스에 조건절 컬럼이 없어서 무시됨)
explain
select /*+ indexscan(a pg_stat_statements_hist_ix1) */*
from sk.pg_stat_statements_hist a
where snap_id = 30
;
QUERY PLAN
--------------------------------------------------------------------------------------------------
Seq Scan on pg_stat_statements_hist a (cost=10000000000.00..10000008613.46 rows=3293 width=299)
Filter: (snap_id = 30)
(2 rows)
-- ix3 인덱스 사용
explain
select /*+ indexscan(a pg_stat_statements_hist_ix3) */*
from sk.pg_stat_statements_hist a
where snap_id = 30
;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------
Index Scan using pg_stat_statements_hist_ix3 on pg_stat_statements_hist a (cost=0.29..261.92 rows=3293 width=299)
Index Cond: (snap_id = 30)
(2 rows)
3.2 leading : 조인 순서 변경
-- 건수가 더 많은 a 테이블을 해시테이블(input table)로 생성하는 실행계획
explain
select *
from sk.tab1 a, sk.tab2 b
where 1=1
and a.queryid = b.queryid
;
QUERY PLAN
--------------------------------------------------------------------------
Hash Join (cost=656.00..15196.05 rows=314269 width=603)
Hash Cond: (a.queryid = b.queryid)
-> Seq Scan on tab1 a (cost=0.00..6557.10 rows=124910 width=300)
-> Hash (cost=531.00..531.00 rows=10000 width=303)
-> Seq Scan on tab2 b (cost=0.00..531.00 rows=10000 width=303)
(5 rows)
-- 작은 테이블 b를 해시테이블로 만들어 조인하는 실행계으로 변경
explain
select /*+ leading((b a)) */ *
from sk.tab1 a, sk.tab2 b
where 1=1
and a.queryid = b.queryid
;
QUERY PLAN
----------------------------------------------------------------------------
Hash Join (cost=13120.48..26735.67 rows=314269 width=603)
Hash Cond: (b.queryid = a.queryid)
-> Seq Scan on tab2 b (cost=0.00..531.00 rows=10000 width=303)
-> Hash (cost=6557.10..6557.10 rows=124910 width=300)
-> Seq Scan on tab1 a (cost=0.00..6557.10 rows=124910 width=300)
(5 rows)
3.3 nestloop : NL JOIN 사용
-- hash join → nl join 으로 변경
explain
select /*+ nestloop(a b) */ *
from sk.tab1 a, sk.tab2 b
where 1=1
and a.queryid = b.queryid
;
QUERY PLAN
-------------------------------------------------------------------------------------
Nested Loop (cost=0.30..32717.37 rows=314269 width=603)
-> Seq Scan on tab1 a (cost=0.00..6557.10 rows=124910 width=300)
-> Memoize (cost=0.30..0.38 rows=4 width=303)
Cache Key: a.queryid
Cache Mode: logical
-> Index Scan using tab2_ix1 on tab2 b (cost=0.29..0.37 rows=4 width=303)
Index Cond: (queryid = a.queryid)
(7 rows)
-- nl join 및 조인 순서 변경
explain
select /*+ leading((b a)) nestloop(a b) */ *
from sk.tab1 a, sk.tab2 b
where 1=1
and a.queryid = b.queryid
;
QUERY PLAN
--------------------------------------------------------------------------------
Nested Loop (cost=0.42..35546.00 rows=314269 width=603)
-> Seq Scan on tab2 b (cost=0.00..531.00 rows=10000 width=303)
-> Index Scan using tab1_ix1 on tab1 a (cost=0.42..3.22 rows=28 width=300)
Index Cond: (queryid = b.queryid)
(4 rows)
3.4 hashjoin : HASH JOIN 사용
-- nl join 실행계획
explain
select *
from sk.tab1 a, sk.tab2 b
where 1=1
and a.snap_id = 30
and a.queryid = b.queryid
and a.snap_id = b.snap_id
;
QUERY PLAN
---------------------------------------------------------------------------------
Nested Loop (cost=0.70..247.74 rows=1 width=603)
-> Index Scan using tab2_ix1 on tab2 b (cost=0.29..239.29 rows=1 width=303)
Index Cond: (snap_id = 30)
-> Index Scan using tab1_ix1 on tab1 a (cost=0.42..8.44 rows=1 width=300)
Index Cond: ((queryid = b.queryid) AND (snap_id = 30))
(5 rows)
-- nl join → hash join, b table full scan, b 테이블 해시테이블로 생성
explain
select /*+ hashjoin(a b) leading((b a)) seqscan(b) */ *
from sk.tab1 a, sk.tab2 b
where 1=1
and a.snap_id = 30
and a.queryid = b.queryid
and a.snap_id = b.snap_id
;
QUERY PLAN
--------------------------------------------------------------------------
Hash Join (cost=6907.99..7464.41 rows=1 width=603)
Hash Cond: (b.queryid = a.queryid)
-> Seq Scan on tab2 b (cost=0.00..556.00 rows=1 width=303)
Filter: (snap_id = 30)
-> Hash (cost=6869.38..6869.38 rows=3089 width=300)
-> Seq Scan on tab1 a (cost=0.00..6869.38 rows=3089 width=300)
Filter: (snap_id = 30)
(7 rows)
여러 테이블 조인 순서 및 방식
explain
select *
from sk.tab1 a, sk.tab2 b, sk.tab3 c
where a.snap_id = 30
and a.queryid = b.queryid
and a.queryid = c.queryid
;
QUERY PLAN
-------------------------------------------------------------------------------------------
Hash Join (cost=656.43..19394.33 rows=240038 width=903)
Hash Cond: (a.queryid = b.queryid)
-> Nested Loop (cost=0.43..12641.09 rows=95404 width=600)
-> Seq Scan on tab3 c (cost=0.00..6636.57 rows=126257 width=300)
-> Memoize (cost=0.43..0.63 rows=1 width=300)
Cache Key: c.queryid
Cache Mode: logical
-> Index Scan using tab1_ix1 on tab1 a (cost=0.42..0.62 rows=1 width=300)
Index Cond: ((queryid = c.queryid) AND (snap_id = 30))
-> Hash (cost=531.00..531.00 rows=10000 width=303)
-> Seq Scan on tab2 b (cost=0.00..531.00 rows=10000 width=303)
(11 rows)
-- c 테이블 a 테이블 hash join 후 b 테이블 nl join
explain
select /*+ leading(((c a) b)) hashjoin(a c) nestloop(a b c) */*
from sk.tab1 a, sk.tab2 b, sk.tab3 c
where a.snap_id = 30
and a.queryid = b.queryid
and a.queryid = c.queryid
;
QUERY PLAN
-------------------------------------------------------------------------------------
Nested Loop (cost=6908.28..74880.83 rows=240038 width=903)
-> Hash Join (cost=6907.99..66737.43 rows=95404 width=600)
Hash Cond: (c.queryid = a.queryid)
-> Seq Scan on tab3 c (cost=0.00..6636.57 rows=126257 width=300)
-> Hash (cost=6869.38..6869.38 rows=3089 width=300)
-> Seq Scan on tab1 a (cost=0.00..6869.38 rows=3089 width=300)
Filter: (snap_id = 30)
-> Memoize (cost=0.30..0.97 rows=4 width=303)
Cache Key: a.queryid
Cache Mode: logical
-> Index Scan using tab2_ix1 on tab2 b (cost=0.29..0.96 rows=4 width=303)
Index Cond: (queryid = a.queryid)
(12 rows)
4. Hints list
출처 : https://github.com/ossc-db/pg_hint_plan/blob/master/docs/hint_list.md
'DBMS > PostgreSQL' 카테고리의 다른 글
| [PostgreSQL] pg_basebackup 사용 백업/복구 테스트 (2) | 2023.11.24 |
|---|---|
| [PostgreSQL] 아카이브 모드 설정 (1) | 2023.11.19 |
| [PostgreSQL] timescaledb extension 설치 (0) | 2023.11.15 |
| PostgreSQL 외부 접속 허용 설정 (0) | 2023.11.08 |
| [PostgreSQL] 백업/복구(pg_dump, pg_restore) (0) | 2023.02.02 |
댓글